

5 estrategias para aumentar el rendimientos de tus APIs 10x
Desbloquea el potencial de tus APIs: Estrategias prácticas para un rendimiento excepcional, Parte 1

👋 ¡Hola! Soy Brian, un Software Engineer con experiencia en desarollo Fullstack y enfoque actual en tecnologías serverless con AWS. Mi dedicación a la innovación se refleja no solo en mi trabajo, sino también en mi pasión por compartir conocimiento sobre desarrollo y la industria Tech.
Explora conmigo este espacio donde comparto ideas, experiencias y consejos en el fascinante mundo del desarrollo de software. 💻💡 Conéctate para seguir descubriendo las últimas tendencias y técnicas en el ámbito tecnológico.
¿Alguna vez has sentido que tus APIs están al borde del colapso, la demanda cada vez crece mas y los tiempos de respuesta rozando lo inaceptable? No te preocupes, no estás solo en esta lucha por la eficiencia. En el mundo de la tecnología, tocar techo es solo el primer paso para alcanzar nuevas alturas.
En este artículo, te presentamos cinco estrategias probadas y efectivas para mejorar el rendimiento de tus APIs, ¡multiplicando su eficacia hasta 10 veces! sin importar el lenguaje o framework, son reglas generales que puedana ayudarte a escribir un codigo eficiente.
Almacenamiento en cache
La idea de usar el cache es simple, utilizar esta capa para evitar ir a la base de datos a buscar datos que no cambian tan frecuentemente, de esta manera podemos acceder a ellos mas rapido.
Si no tengo los datos en la cache, lo obtengo de la BD y lo guardo en la cache y las posteriores request reduciran la latencia y evitaran usar recursos de la Base de datos.

Es importante manejar un tiempo establecido para invalidar esa cache y buscar de nuevo los datos, tambien actualizar la cache cuando los datos se modifican. Al principio podria ser un desafio, pero a medida que va creciendo las peticiones, tu API lo agradecera.
esta estrategias para manejar mas de 5 millones de lectura de perfiles por segundo.Load balancer y escalamiento horizontal
Si una instancia de un servidor no es suficiente para tu API, podrias considerar usar mas instancia de servidores.
Ahora el problema es que necesitamos un componente para poder distribuir las peticiones a estos servidores de manera equitativa y correcta, priorizando la eficienca de recursos y evitando la saturacion de las instancias.
Un load balancer ayudara precisamente a esto, a orquestar las peticiones que lleguen a tu API de manera equitativa a las intancias de servidores que se encuentren disponibles, esta estrategia es ideal si quieres un escalamiento horizontalen tu servicios.
Este patron funciona mejorar en aplicaciones stateless

Uso de flujos asincronos
Esta solución es perfecta para aquellas tareas en las que no requerimos una respuesta inmediata ni sincrónica con su ejecución.
Imagina que en tu aplicación necesitas enviar correos electrónicos de confirmación después de que un usuario complete cierta acción, como registrarse en el sitio o realizar una compra. En lugar de esperar la respuesta del servidor de correo antes de continuar con otras tareas, puedes hacer que el envío de correos electrónicos sea asíncrono.
Otro ejemplo, supongamos que tu aplicación necesita generar informes complejos o realizar análisis de datos intensivos, como el reporte de los 3 meses en las transacciones que realizo un usuario, estas tareas pueden consumir una cantidad significativa de recursos y tiempo de procesamiento. Utilizar flujos asíncronos para manejar la generación de informes y análisis de datos permite que los usuarios continúen utilizando la aplicación sin interrupciones mientras se llevan a cabo estas tareas en segundo plano.
Algunos servicios que son ideales para utilizar con este patron son AWS SQS, SNS, O RabbitMQ (este ultimo opensource) y pueden ayudarte y mejorar los tiempos de latencia enormemente.
Puede responder al cliente con un estatus 202, luego a traves de un webhook / callback, confirmar el resultado del procesamiento.

Paginacion
Aqui aplico de nuevo el refran que me gusta
Divide y venceras
Imagina que estás en una tienda de ropa y hay muchos marcas disponibles. Si el vendedor intentara darte todos los marcas al mismo tiempo, te sentirías abrumado y probablemente no de tiempo de procesar todo, ¿verdad? La paginación en una API es como dividir esas marcas en pequeños grupos. En lugar de mostrarte todos las marcas de una vez, te los presentan de a poco, en páginas.
Incluso Google lo tenia en su momento para las busquedas, ahora usan un sistema mas parecido al infinity scrolling (que al final no deja de ser lo mismo solo que de una manera mas fancy)

Esto hace que no generemos una query mas pesada al obtener todos los datos de la base de datos, los datos transferidos al cliente sean menos y por ende sean mas rapido la respuesta.

Manejo eficiente de las conexiones con Base de datos
Por lo general nuestras APIs necesitan conectarse a una base de datos. Crear esta conexion genera un impacto en el rendimiento.
Una implementacion para mejorar el rendimiento seria crear un pool de conexiones. Es decir, crear un servicio especializado y centralizo en verificar si existe una instancia aun viva de la BD antes de crear una, de esta manera no estamos abriendo una conexion nueva por cada request/cliente.

Parece algo innecesario, pero esto tiene mayor efectos en sistemas que requieran una alta concurrencia, esto podria realizar un impacto bastante grande.
Por ejemplo, este es el caso de uso de un desarollador que se dio cuenta de esto y compartio sus hallazgos
En su aplicacion stateless por cada nueva peticion abria una nueva conexion a la base de datos, en promedio recibia 300 invocaciones HTTP, esto se traducia en que el sistema de conexiones de Mysql estuviera siempre bajo estres y llegando casi al tope de los limites establecidos.
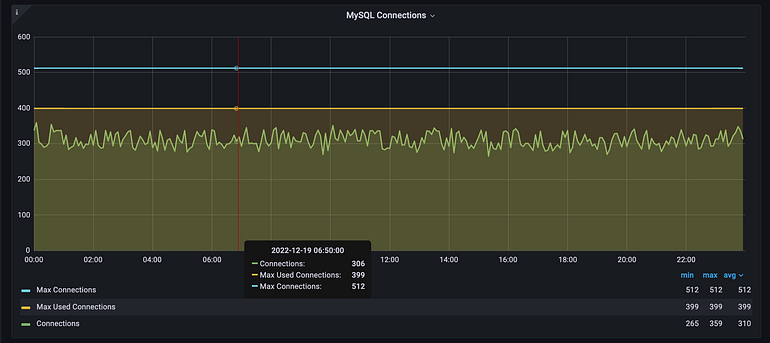
Al darse cuenta de esto, realizo la implementacion que se comenta y logro reducir notablemente el performance y por ende los $$ que generaba por abrir una conexion nueva.
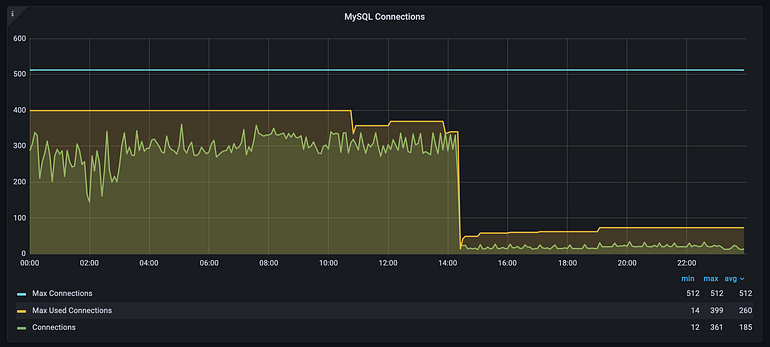
Paso de 399 como maximo 14 conexiones. Este un claro ejemplo del impacto que podria tener en sus APIS.
¡Gracias por llegar hasta aquí!

Espero que estas estrategias te hayan resultado útiles y que puedas aprovecharlas al máximo en tu desarrollo. También quiero contarte que he creado una versión en video de esta primera parte del artículo, la cual he compartido en mis cuentas de Instagram y YouTube. ¡No te pierdas las novedades que voy subiendo!
No olvides seguirme en mis redes sociales para estar al tanto de todas las novedades. Además, suscríbete a la newsletter para recibir las últimas actualizaciones directamente en tu bandeja de entrada. ¡Nos vemos en la próxima entrega!


